 SWE-bench
SWE-bench

Overview
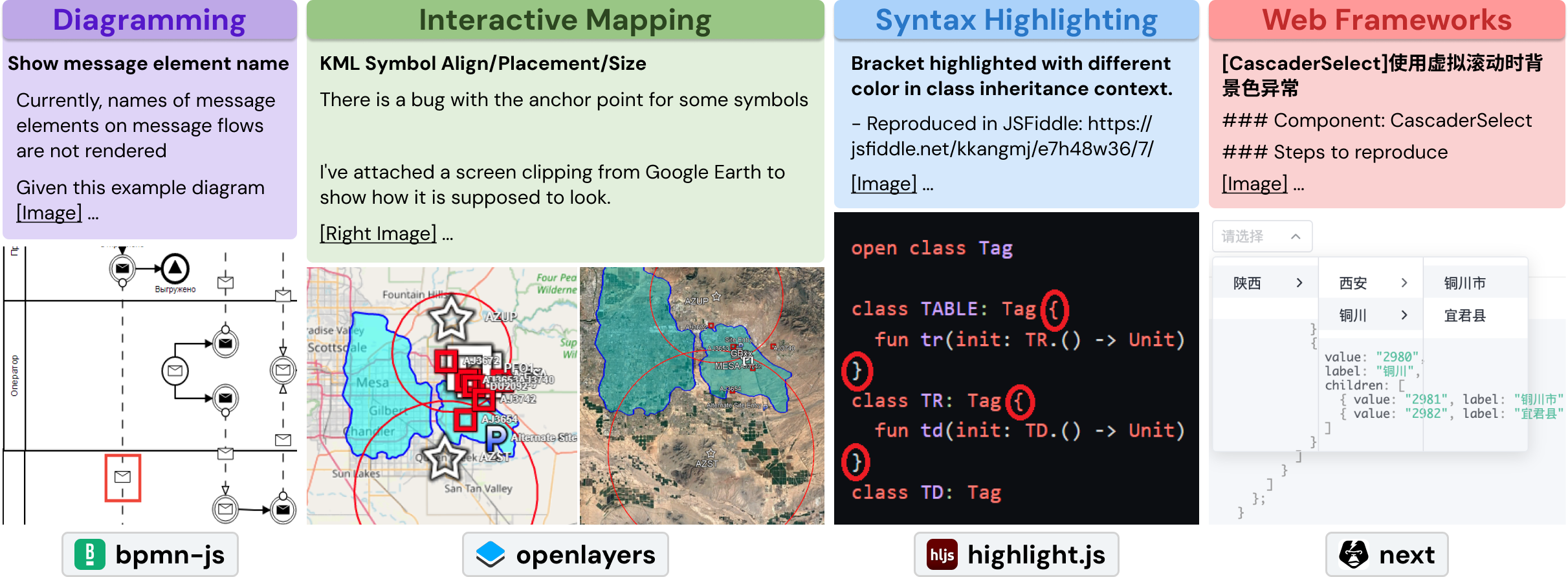
SWE-bench Multimodal augments the original benchmark with 517 issues that contain visual elements such as:
- Screenshots of bugs or interface issues
- Design mockups or wireframes
- Diagrams explaining desired functionality
- Error messages with visual context
This extension evaluates models' ability to interpret and act on information presented in both textual and visual formats.
Correspondence
For questions about SWE-bench Multimodal, please contact:
Citation
If you use SWE-bench Multimodal in your research, please cite our paper:
@inproceedings{yang2025swebench,
title={SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?},
author={John Yang and Carlos E Jimenez and Alex L Zhang and Kilian Lieret and Joyce Yang and Xindi Wu and Ori Press and Niklas Muennighoff and Gabriel Synnaeve and Karthik R Narasimhan and Diyi Yang and Sida Wang and Ofir Press},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=riTiq3i21b}
}
Yang, J., Jimenez, C. E., Zhang, A. L., Lieret, K., Yang, J., Wu, X., Press, O., Muennighoff, N., Synnaeve, G., Narasimhan, K. R., Yang, D., Wang, S. I., & Press, O. (2024). SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? arXiv preprint arXiv:2410.03859.
Yang, John, et al. "SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?" arXiv preprint arXiv:2410.03859 (2024).